Detección de anomalías en industria: límites de los enfoques académicos
La detección de anomalías es una de las tareas más atractivas —y a la vez más complejas— dentro de la visión artificial industrial. El objetivo es aparentemente sencillo: aprender cómo es un producto correcto y detectar cualquier desviación significativa respecto a ese comportamiento normal. En entornos industriales, donde los defectos son raros, cambiantes y difíciles de catalogar, esta aproximación resulta especialmente tentadora.
De ahí surge el interés por los métodos no supervisados o one-class: sistemas que se entrenan únicamente con imágenes OK, sin necesidad de ejemplos de defecto (NG). En teoría, estos métodos permiten desplegar sistemas de inspección robustos incluso cuando no se dispone de datos de fallos, algo muy habitual en planta.
En los últimos años, este enfoque ha ganado popularidad en el ámbito académico gracias a frameworks como Anomalib, una librería open-source impulsada por Intel y la comunidad investigadora. Anomalib implementa y estandariza una serie de métodos de detección de anomalías ampliamente citados en la literatura, como PaDiM, PatchCore, STFPM o FastFlow, entre otros. Estos modelos se apoyan en redes convolucionales preentrenadas para extraer representaciones profundas y modelar estadísticamente lo que consideran “normal”.
Sobre el papel, la propuesta es muy atractiva: entrenar solo con piezas buenas, sin etiquetado manual, y obtener no solo un score de anomalía sino también mapas de calor que supuestamente explican dónde está el problema. No es casualidad que estos métodos dominen benchmarks públicos como MVTec Anomaly Detection, donde reportan resultados excelentes.
Sin embargo, la industria real no es un benchmark.
En la práctica industrial, estos enfoques fallan de forma sistemática fuera de escenarios muy controlados. No por falta de calidad técnica, sino porque el problema que están resolviendo no se corresponde con el problema que existe en planta. El dataset de referencia condiciona el diseño de los modelos, y ese dataset no representa la realidad industrial.
En este artículo explicamos por qué los métodos popularizados por anomalib no son utilizables en la mayoría de casos industriales reales, por qué el uso masivo de un único dataset está desviando a toda la comunidad hacia soluciones poco prácticas, y cómo un enfoque mucho más simple —basado en la correcta localización del objeto y en comparaciones directas de descriptores— ofrece mejores resultados, menor complejidad y mayor robustez en producción.
A lo largo del post compararemos directamente PaDiM, PatchCore y nuestro enfoque, primero sobre datasets públicos y después sobre un caso real de industria, mostrando con datos y ejemplos por qué, en detección de anomalías, menos suele ser más.
1) Qué propone Anomalib y por qué resulta convincente
Modelos como PaDiM o PatchCore siguen un esquema común:
- Extraen embeddings locales mediante una red preentrenada.
- Construyen una representación estadística de lo “normal” usando solo imágenes OK.
- En inferencia, comparan cada parche de la imagen contra ese modelo.
- Devuelven un score global y, opcionalmente, un mapa de calor con zonas “sospechosas”.
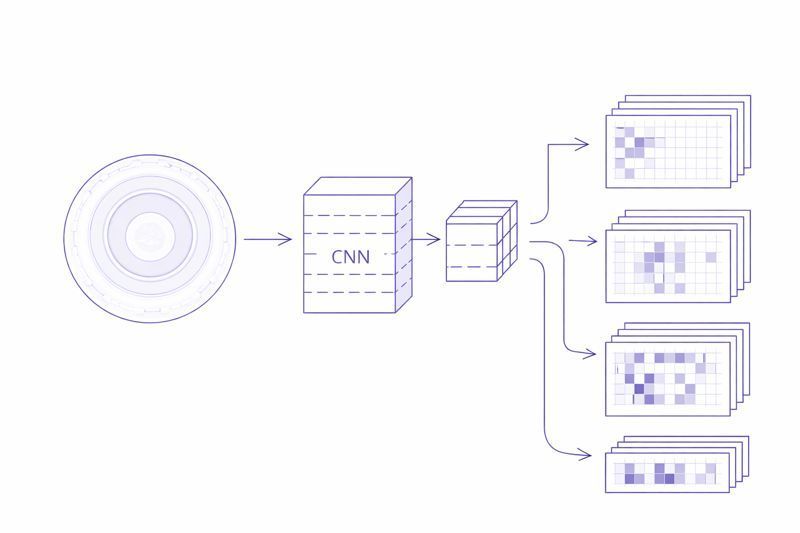
Extracción de features
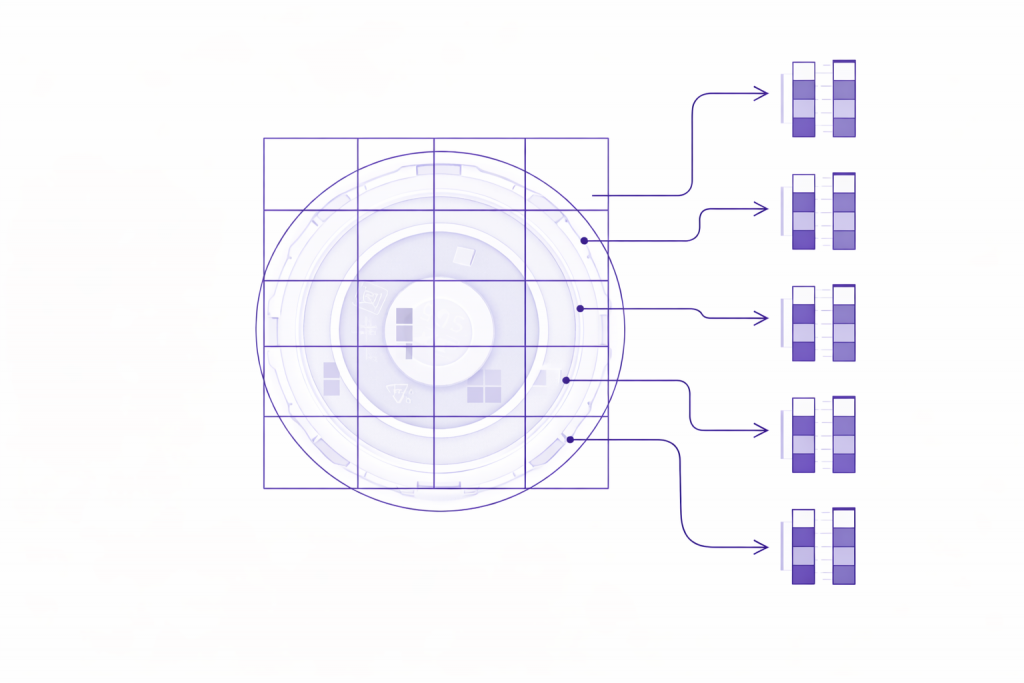
Representación local por patches,cada zona se evalúa de forma independiente
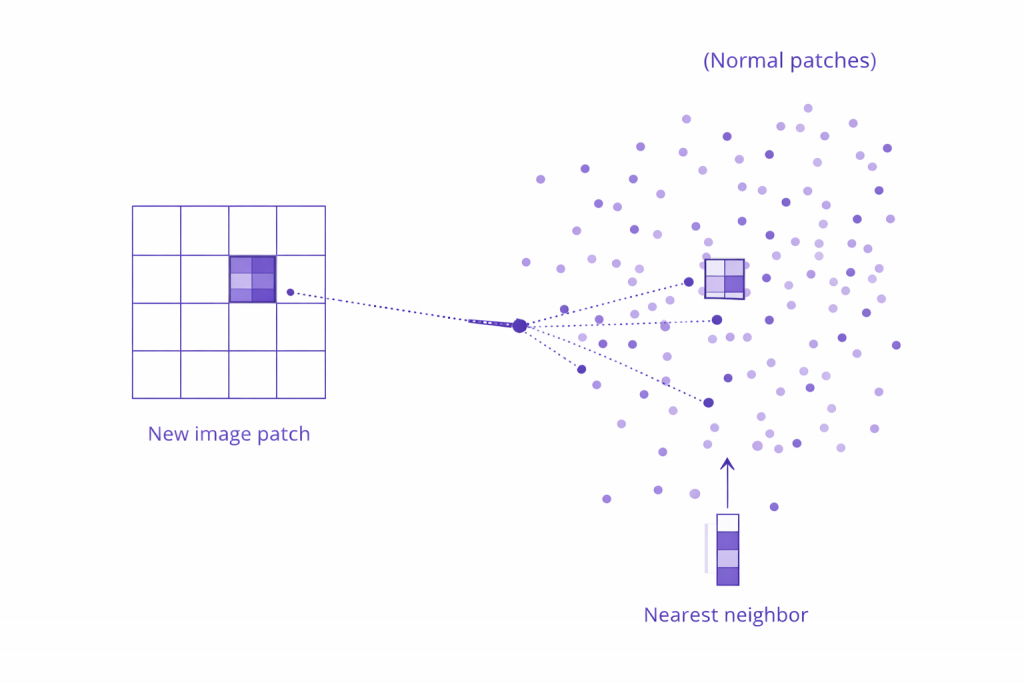
PatchCore – comparación con memoria: esto se parece a lo que ya he visto o no
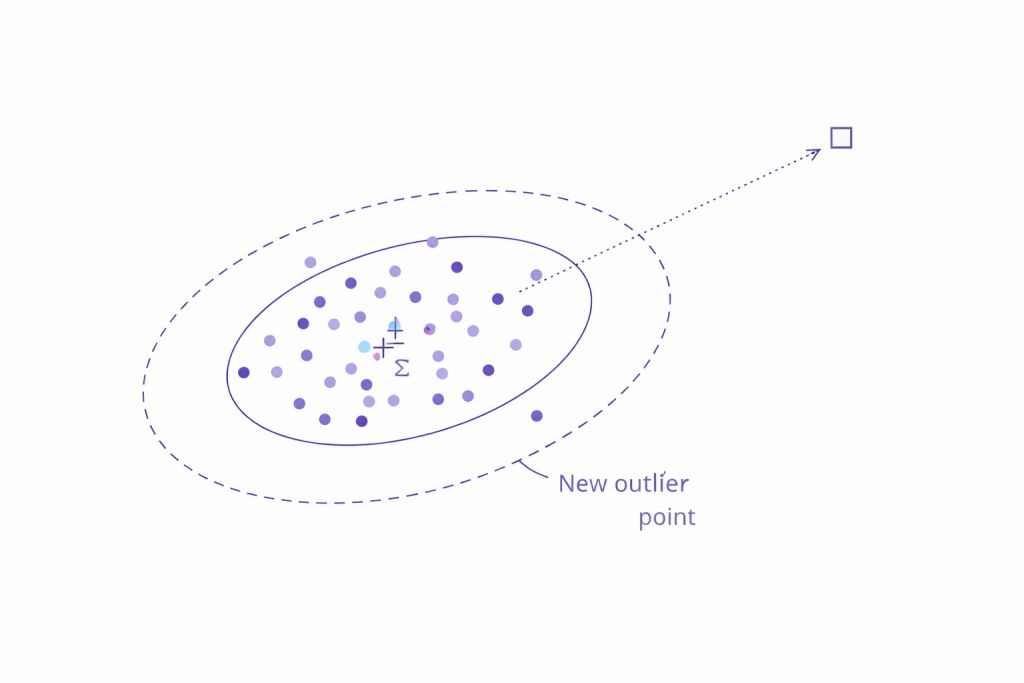
PaDiM – modelo estadístico: esto se sale de la distribución normal
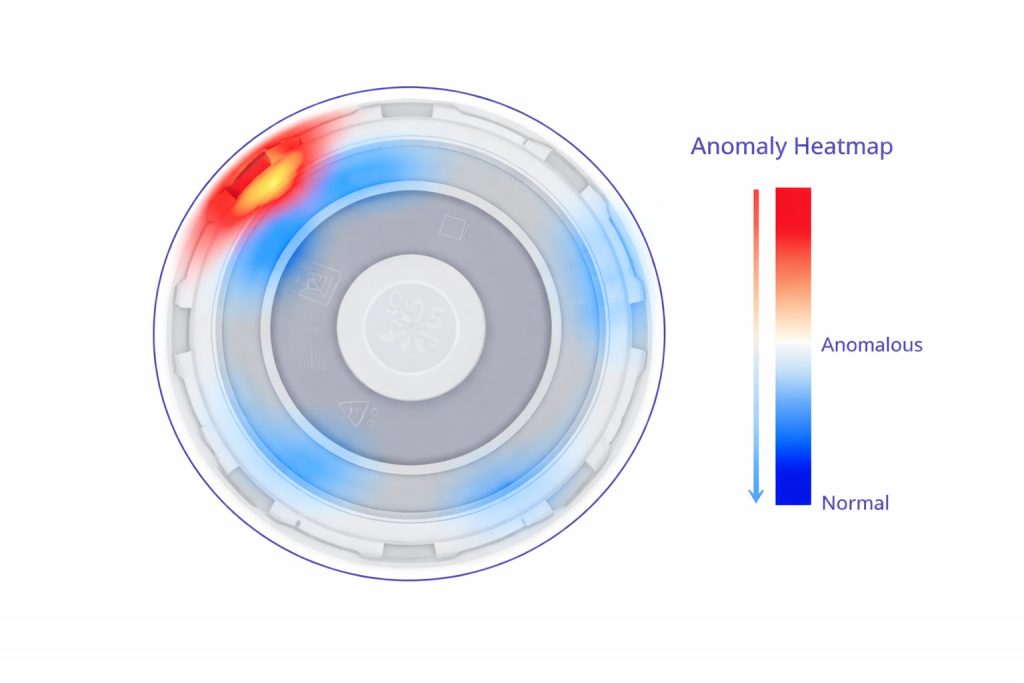
Mapa de anomalía final: detección local → decisión global
El problema no es el modelo.
El problema es el contexto en el que se evalúa.
2) La realidad industrial: Anomalib no es usable
2.1) Solo funciona bien en casos muy concretos
En nuestras pruebas —y en experiencia real de planta— Anomalib solo se comporta de forma aceptable cuando se cumplen condiciones muy restrictivas:
- Texturas homogéneas (tela, cuero, superficies continuas).
- Objetos perfectamente posicionados, sin rotación ni desplazamiento.
- Fondo absolutamente estable.
- Iluminación muy controlada.
Estos casos existen, pero son minoría en industria.
2.2) El modelo no entiende el objeto
PaDiM y PatchCore no saben qué es la pieza. Modelan la imagen completa. Eso implica que cualquier cambio en el fondo se convierte en “defecto”, y pequeñas variaciones geométricas se penalizan. En industria el fondo nunca es perfectamente estable: el enfoque falla por diseño.
3) El dataset MVTec: el gran problema del campo
3.1) Un dataset poco industrial
MVTec Anomaly Detection contiene ejemplos como tornillos sueltos perfectamente centrados, cápsulas en la misma posición o texturas extremadamente estables, con muy poca variabilidad. Eso no representa una línea industrial real.
3.2) Se optimiza para el dataset, no para la industria
No cuestionamos la capacidad de los investigadores. Cuestionamos el marco de referencia: cuando toda la comunidad evalúa sobre un dataset irreal, los modelos mejoran… para ese dataset, pero no se acercan al problema real.
4) Los mapas de calor: bonitos, pero inútiles
Los mapas de calor funcionan muy bien en demos y presentaciones. En producción, rara vez aportan valor:
- El ojo humano localiza el defecto antes.
- Para decidir OK / NG lo relevante es un score global estable.
- Un heatmap añade coste y complejidad sin mejorar la decisión industrial.
5) Anomalib como software: experimental, no industrial
Más allá del modelo, Anomalib es código experimental pensado para investigación: dependencias pesadas, configuración frágil y mantenimiento complejo. Para lo poco que aporta frente a métodos más simples, no compensa.
6) Nuestro enfoque en Arin Apin
En Arin Apin hemos seguido el camino contrario: menos magia, más control.
- Localizar y aislar el objeto (alineación + máscara).
- Extraer embeddings globales del objeto.
- Construir un conjunto amplio de referencias OK.
- Comparar mediante distancia de coseno (y variantes).
- Decidir con un score global.
Ejemplo simplificado del núcleo del método:
similarities = []
for e_ok in vectores_ok:
sim = cosine_similarity(e_ok, embedding_actual)
similarities.append(sim)
score = np.mean(similarities)Sin parches, sin mapas de calor, sin modelos pesados.
7) Comparativa directa con PaDiM y PatchCore
Hemos comparado nuestro método con PaDiM y PatchCore en tres escenarios:
- Imágenes crudas (raw)
- El mismo dataset con máscara
- El mismo dataset con máscara + recorte cuadrado
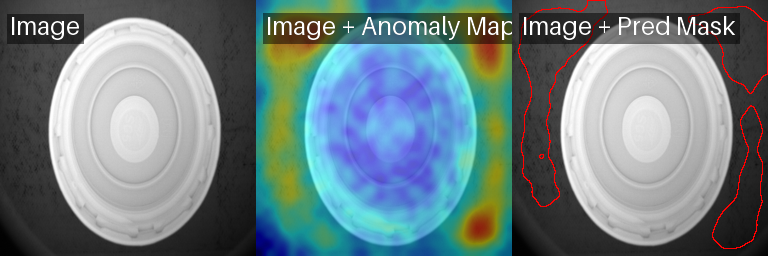
PatchCore sobre una imagen OK, reaccionando a un fondo inestable (cinta transportadora).
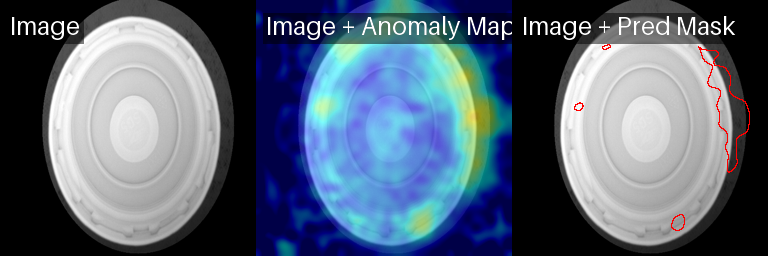
Mismo objeto entrenado y analizado con máscara para descartar el fondo.


Ejemplos de PaDiM reaccionando fuerte a unos defectos mientras no reacciona a otros defectos muy evidentes.

El mismo defecto puede detectarse entrenando y haciendo inferencia con máscara para descartar el fondo.

Otros defectos que son fácilmente detectados por modelos supervisados de clasificación (en este caso es la ausencia de anilla de sellado) no son detectables ni con PaDiM ni PatchCore.
Resultado típico: Anomalib se degrada rápidamente cuando el fondo o la posición varían.
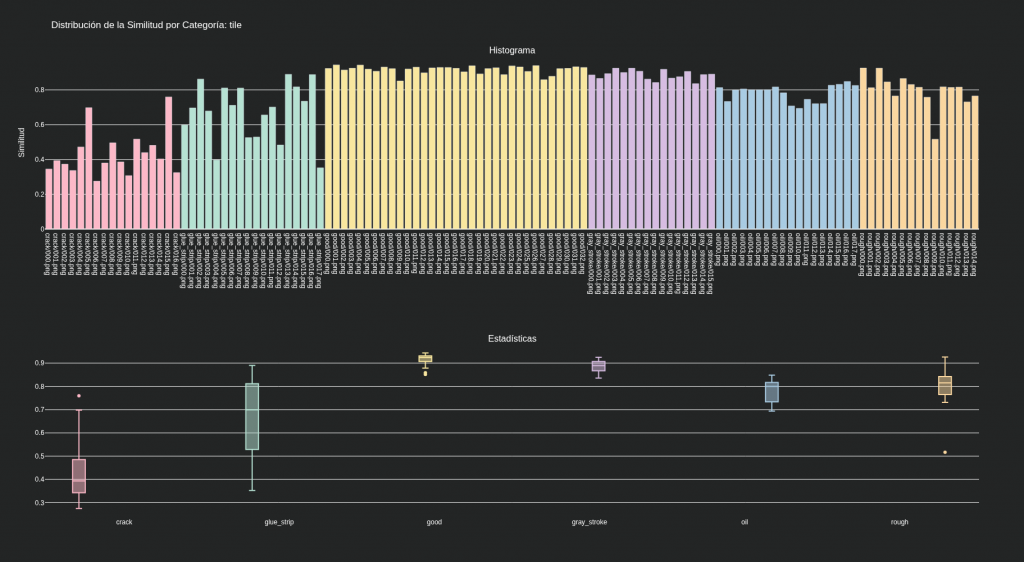
Un método mucho más sencillo como el que proponemos nosotros tiene resultado similares en objetos posicionados o en texturas:
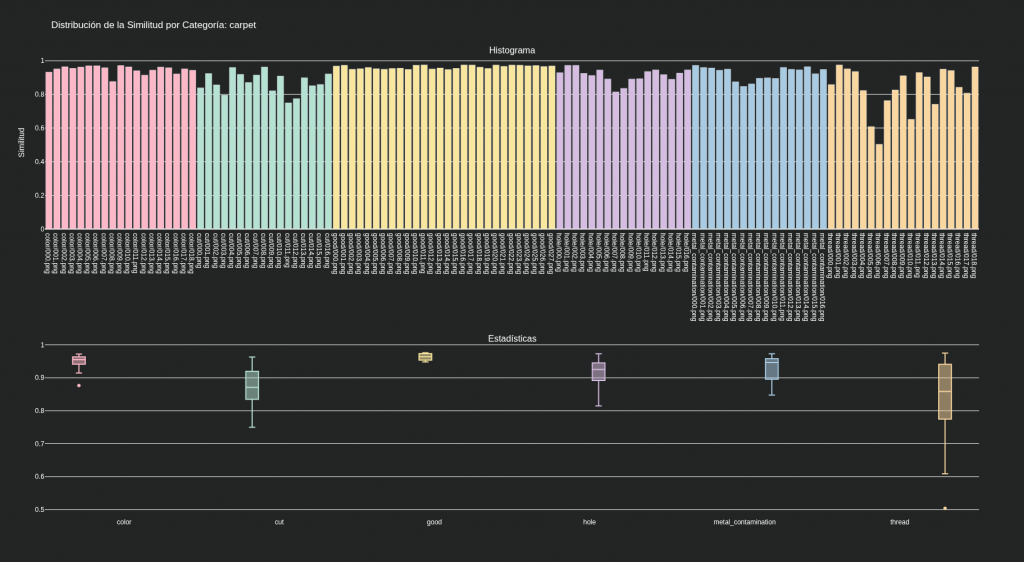
Dataset MVTec categoría carpet:

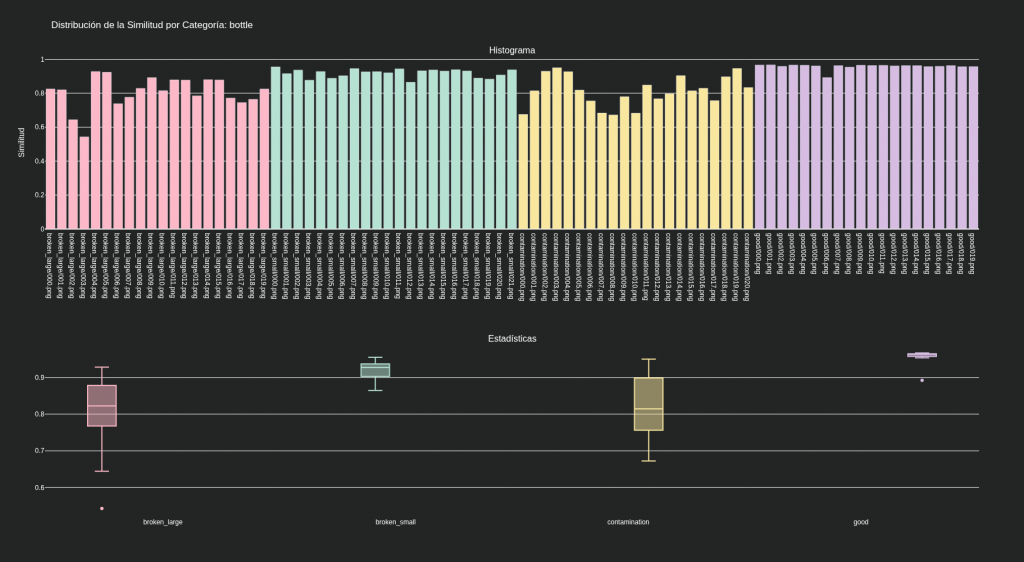
Dataset MVTec categoría bottle:

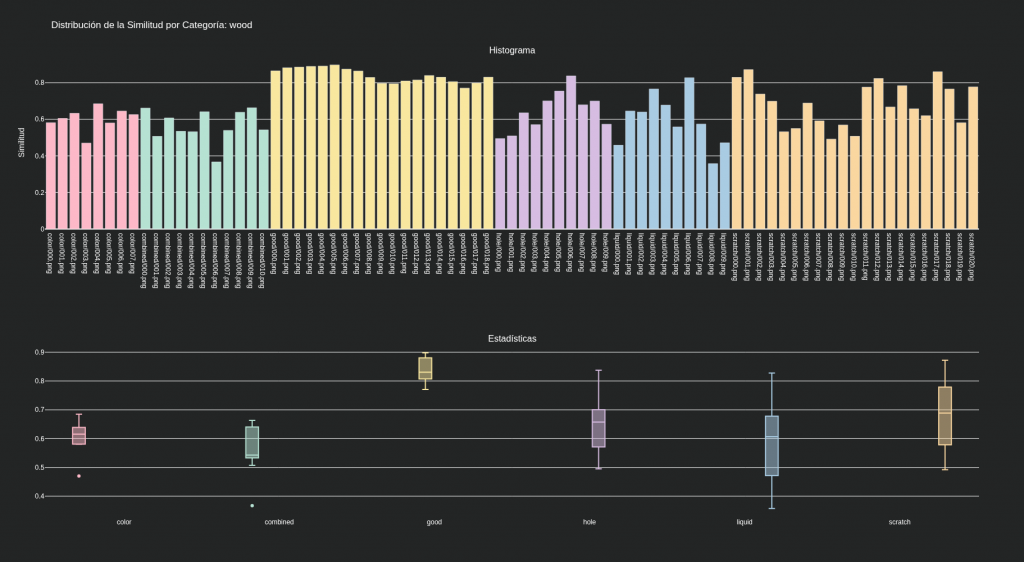
Dataset MVTec categoría wood:

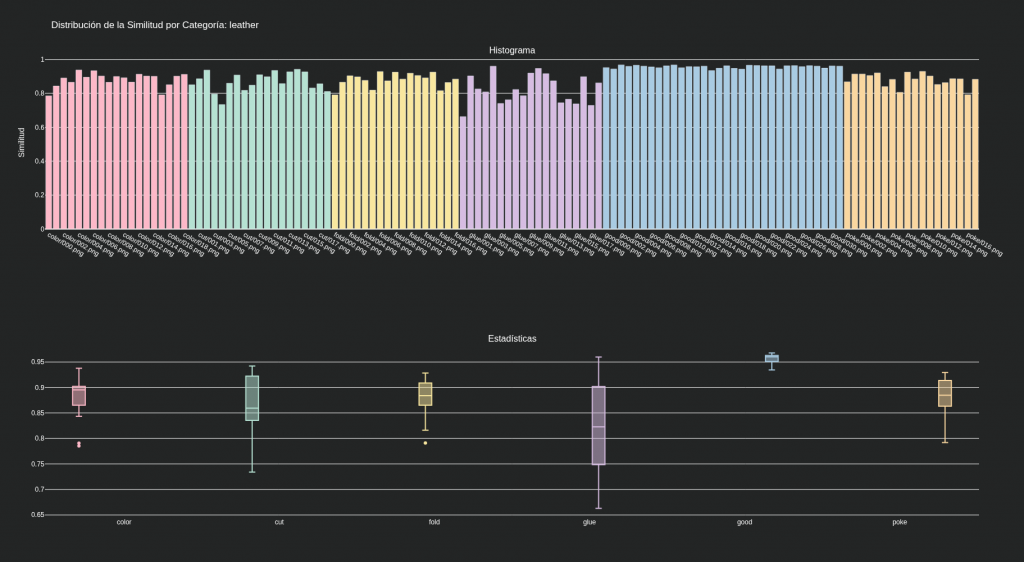
Dataset MVTec categoría leather:

Dataset MVTec categoría tile:
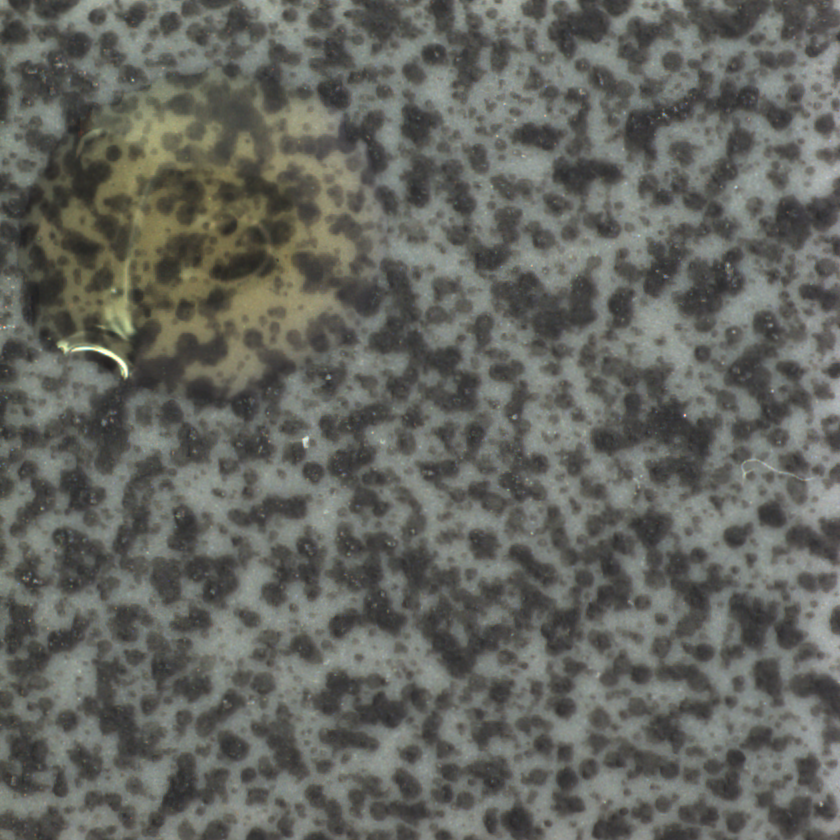
8) El factor clave: posicionamiento y fondo
En detección de anomalías no supervisada, el mayor enemigo es siempre el mismo: variación de posición y variación de fondo. No existe hoy un método infalible que lo resuelva automáticamente. Cuando es necesario usamos alineación clásica (contornos, patrones), detección ligera, o herramientas tipo SAM como asistente (no como runtime).
9) Industrialización: una interfaz pensada para planta
Uno de los mayores problemas de Anomalib es que no está pensado para ser usado. En Arin Apin priorizamos una interfaz donde el aprendizaje es visual, la inferencia es inmediata y el resultado es claro: OK / NG.

Ventana de selección de objetos «GOOD» para entrenamiento.
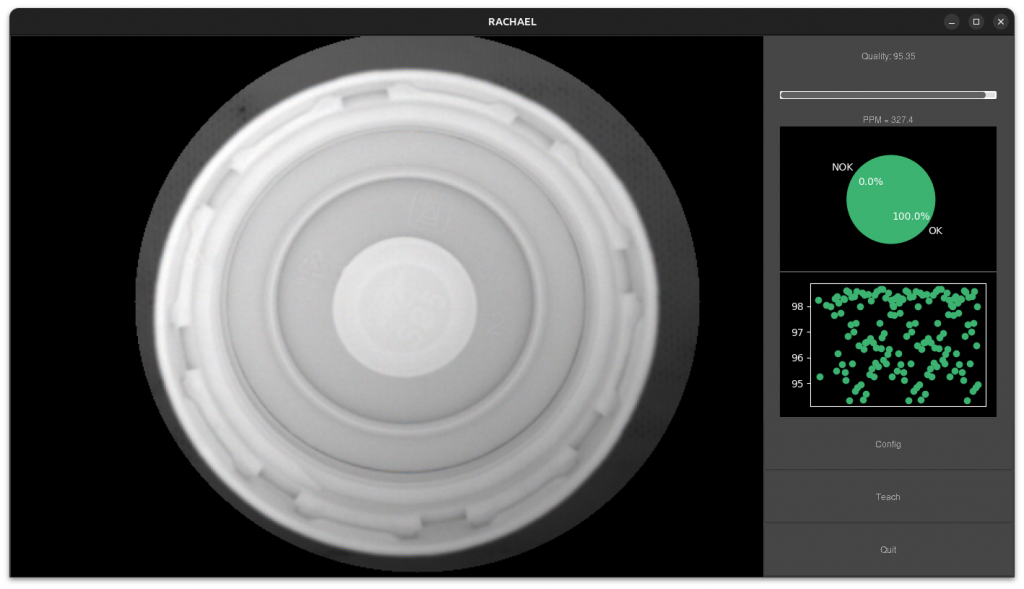
Ventana de inferencia.
Fragmento real (simplificado) del sistema de inferencia:
result = self.image_embedder.infer(pil_image) * 100
if result < self.tolerance * 100:
estado = "NOK"
else:
estado = "OK"Sin librerías inestables. Sin métricas académicas. Sin mapas de calor.
10) Caso real: tapones industriales
Para cerrar, probamos PaDiM, PatchCore y nuestro método sobre un dataset real de tapones industriales (fondo variable, iluminación real, posicionamiento no perfecto). El patrón es consistente: Anomalib genera falsos positivos de forma recurrente; nuestro método se mantiene estable tras aislar el objeto y es usable en producción.

PaDiM: Good

PaDiM: Defecto arandela

PaDiM: defecto «sin arandela»


PaDiM sobre defectos de válvula inclinada
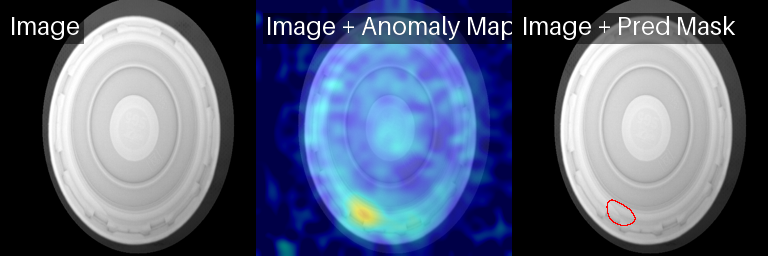
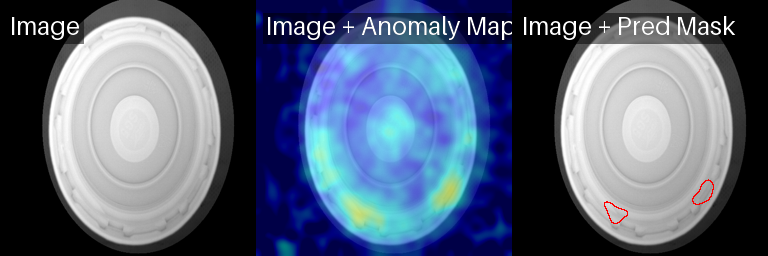
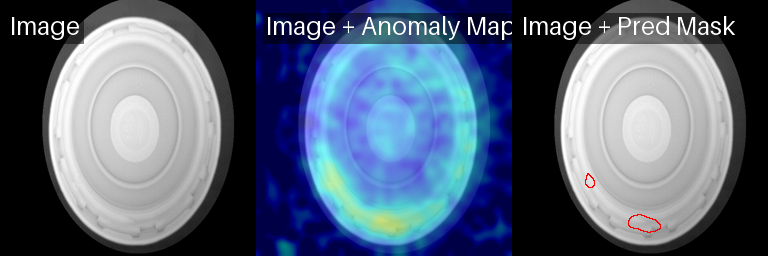
PatchCore sobre objetos good
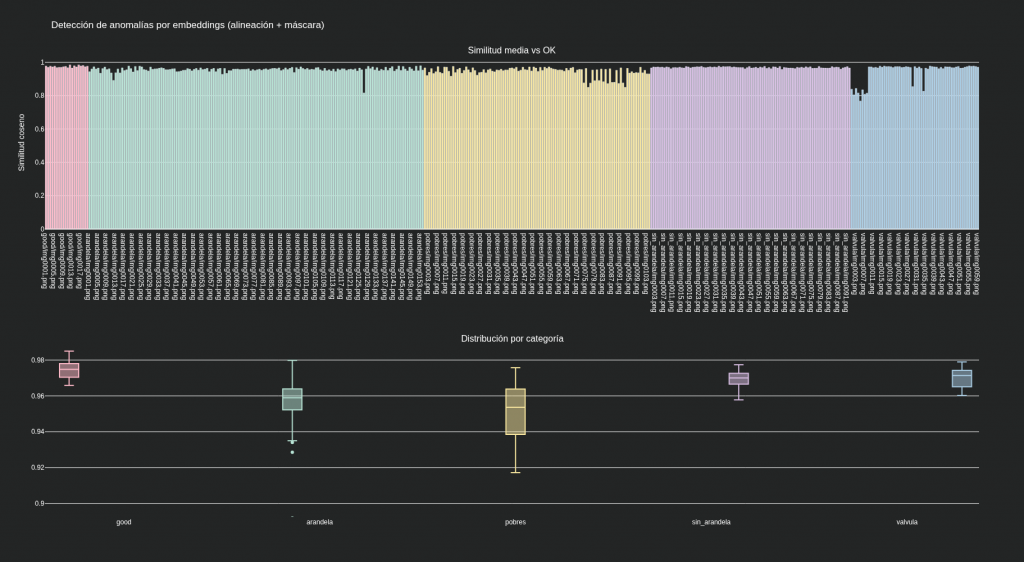
Nuestro método sobre todo el dataset
Según nuestras métricas, con éste y otros datasets, la aplicación de los diferentes modelos de Anomalib no aportan precisión sobre este método mucho más sencillo y sí aportan mucha más inestabilidad, tanto a nivel de falsos positivos como de mantenimiento e implantación.
Conclusión
- El dataset que se usa como referencia no representa la industria.
- Los mapas de calor suelen ser irrelevantes en producción.
- Anomalib es experimental, no preparado para producción.
- El verdadero reto es localizar y aislar el objeto.
- Con un pipeline simple y controlable, no hace falta Anomalib.